
決策樹(Decision Trees)是一個對人們來說相當好想像的機器學習模型,其樣貌為一個由上往下不斷分枝成長的樹狀結構(見圖1),在每一個節點(Node)上,都會進行一次決策的分枝,符合該節點上決策的資料,會被分配至左方的下一個節點,而不符合的資料則會被分配至右方。隨著決策樹不斷地往下分枝成長,各節點下的資料目標值分佈會越趨一致,形成我們的決策考量,在當有新資料進入模型後,我們可以根據決策樹發展完成的決策路徑,一步步地將手上的資料依據對應的特徵值進行判斷,最終知道該資料的目標值為何,且可以用來處理分類與回歸兩種機器學習問題。
那決策樹模型是如何決定該以什麼特徵的什麼值去進行分枝的呢? 決策樹模型在分枝上使用的概念是最大化分枝後的 資訊增益(Information Gain) (註1),也就是假設說原本未分割的資料有兩種類別,且可能彼此數量相當一致,因此我們很難判斷或猜測說每一筆資料到底是屬於什麼類別,但是透過分枝後,在分枝下的節點上,一邊的資料群變得主要由某類別組成,而另一邊的資料幾乎是由另一類別所構成,資訊增益就是其中從原本很難判斷到能夠很清楚判別之間資訊量的差別程度。而在資訊增益程度的判斷標準上,常見的方法我們可以使用 熵(Entropy) (註2)或者 吉尼不純度(Gini Impurity) (註3)來衡量。
決策樹模型比起先前提到的簡單模型有以下好處,比如說可以處理非線性的問題(圖2),以及有非常好理解的模型解釋性,且在機器學習演算法上,還有著許多複雜的模型就是以決策樹為基礎,建構更強大的模型來解決單個決策樹可能準確度不高或者泛化能力不足的問題。
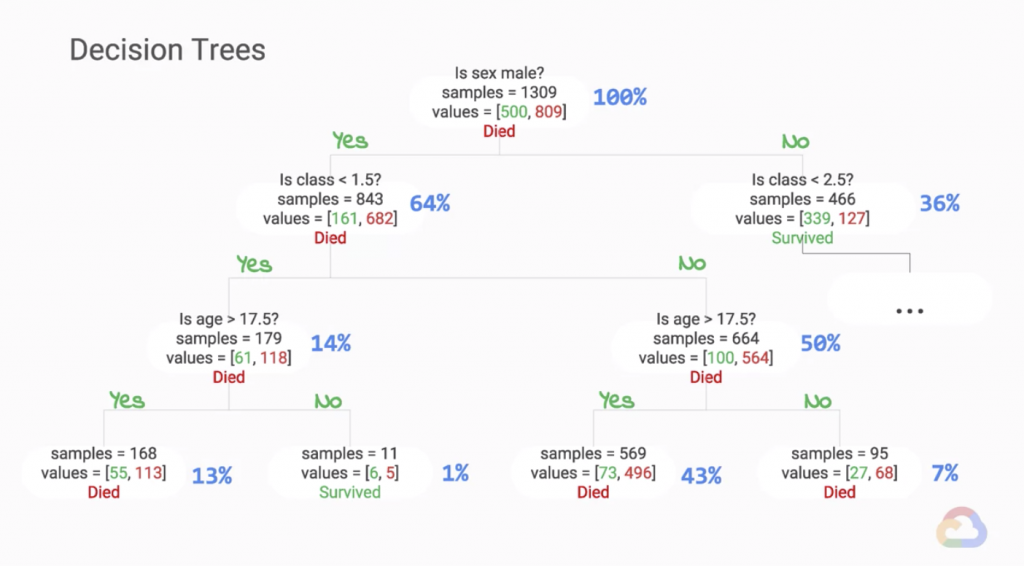
圖1
Source: Coursera - Launching into Machine Learning
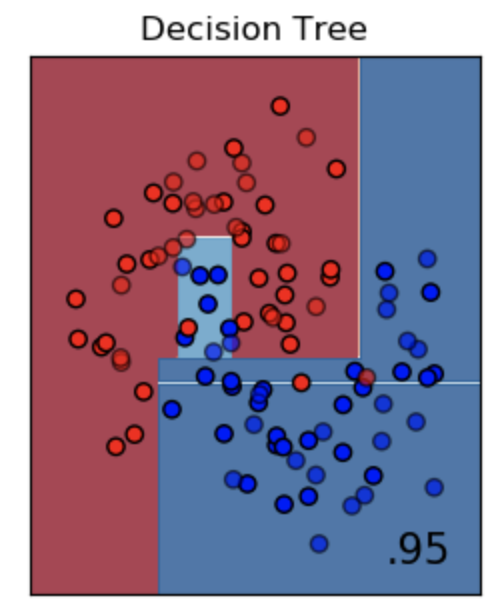
圖2
Source: https://scikit-learn.org/stable/auto_examples/classification/plot_classifier_comparison.html
註1: https://en.wikipedia.org/wiki/Information_gain_in_decision_trees
註2: https://zh.wikipedia.org/wiki/%E5%86%B3%E7%AD%96%E6%A0%91%E5%AD%A6%E4%B9%A0
註3: https://zh.wikipedia.org/wiki/%E5%86%B3%E7%AD%96%E6%A0%91%E5%AD%A6%E4%B9%A0

 iThome鐵人賽
iThome鐵人賽